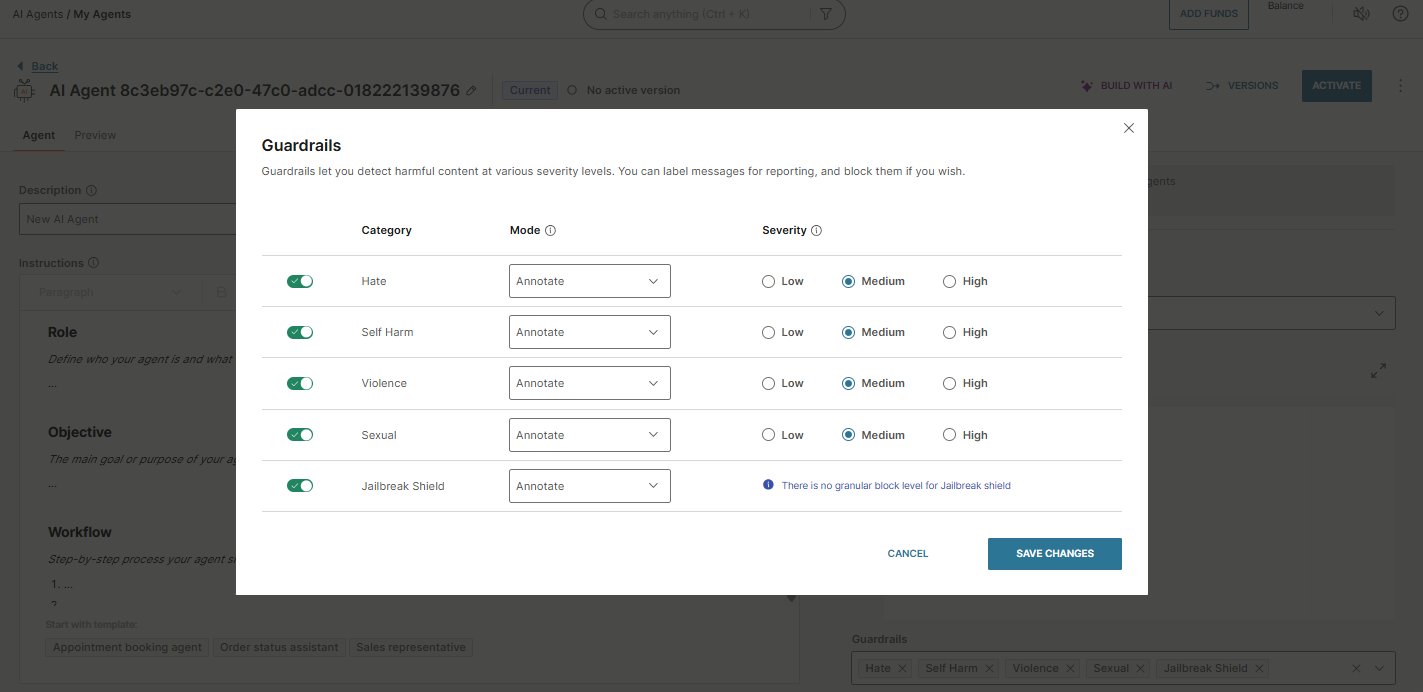
ガードレールを構成する
ガードレールは、エンドユーザーメッセージ内の有害なコンテンツを検出し、エージェントの応答方法を制御します。これらは エージェント設定 の一部です。
より広範な行動計画については、「行動ガイドラインの計画」を参照してください。
フィルタ設定
各ガードレールには、次の 3 つの設定があります。
- カテゴリ
- 重大 度
- モード
カテゴリ [#category-filter-settings]
フィルタリングするコンテンツの種類を選択します。
- 暴力 - 暴力的な言葉や脅迫。
- ヘイト - ヘイトスピーチまたは差別的なコンテンツ。
- 性的 - 露骨または不適切な性的なコンテンツ。
- 自傷行為 - 自傷行為を助長するコンテンツ。
- 脱獄シールド - エージェントを操作したり、安全ガイドラインを回避したりしようとします。
過酷 [#severity-filter-settings]
フィルターの感度:
| 重大度 | 説明 |
|---|---|
| 低 | 軽度の不適切な言葉遣いを検出します。 |
| ミディアム | 中程度の有害な言語を検出します。 |
| 高 | 明示的に有害な言語のみを検出します。 |
手記Not applicable for Jailbreak shield.
モード [#mode-filter-settings]
フィルターがトリガーされたときにエージェントが行うこと:
| モード | 説明 |
|---|---|
| 注釈 | メッセージの通過を許可します。フィルターの一致を Analytics に記録します。 |
| ブロック | メッセージをブロックします。フィルターの一致を Analytics に記録します。 |
| オフ | このカテゴリのフィルターを無効にします。 |
手記
脱獄シールドカテゴリは、重大度レベルを使用しません。欠陥の悪用、安全ガイドラインの回避、事前定義された指示の上書きなど、エンド ユーザーによる AI エージェントを操作しようとする試みを検出します。
ガードレールを設定するには、エージェント設定の ガードレール セクションを開き、各フィルターの カテゴリ、モード、および 重大度 (該当する場合) を設定します。