Web クローラーを使用してドキュメントを生成する
AI アシスタントに追加するドキュメントがすでにオンラインで入手できる場合は、Web サイトをクロールできます。
クロール プロセス [#crawl-process]
クロール プロセスは次のとおりです。
- ドキュメントを含む Web サイトへのリンクを追加します。
- システムは Web サイトをクロールし、ファイルを生成します。
- AI アシスタントの カスタム コンテンツ セクションにファイルをアップロードします。
運用目的では、最良の結果を得るためにドキュメントを手動で準備します。
クローラーの変更されていない出力は、デモ目的でのみ使用してください。
詳細については、次のセクションを参照してください。
ウェブサイトのガイドライン [#website-guidelines]
ウェブサイトをクロールするためのガイドライン [#crawl-guidelines]
- HTML Web サイト形式のみを使用します。
- Web サイトで JavaScript コードまたは API を使用してコンテンツを表示する場合、コンテンツの品質が影響を受ける可能性があります。
- Facebook や Twitter などのソーシャル メディア サイトへのリンクを使用すると、コンテンツの品質が影響を受ける可能性があります。
- AI アシスタントは、リンクとそのページのコンテンツのみを使用します。Webサイトの他の部分のコンテンツは使用しません。
- 関連するコンテンツを含むトップレベルのリンクを使用します。
例: アシスタントが Answers 製品のドキュメントを使用する場合は、
https://www.infobip.com/answers.https://ib.nttcpaas.com/docs, を追加すると、アシスタントはすべての NTT CPaaS 製品のドキュメントを使用します。そのため、アシスタントは正確な応答を生成しない可能性があります。 - コンテンツのスクレイピングは、次のいずれかの制限に達すると停止します。
- 最大 7 MB のコンテンツがスクレイピングされます。
- コンテンツは 2 分間スクレイピングされます。
ウェブサイトのコンテンツ品質に関するガイドライン [#content-guidelines]
次のことは避けてください。
- 複数のトピックを含む Web ページ。
- 同じコンテンツが複数の Web ページに存在します。
- 同じ概念の異なる定義。
- 不正確または重複した情報。
- 同じ Web ページ上の類似の製品またはトピックに関する情報。
クローラーを構成する [#configure-crawler]
[クロール] タブに移動します。
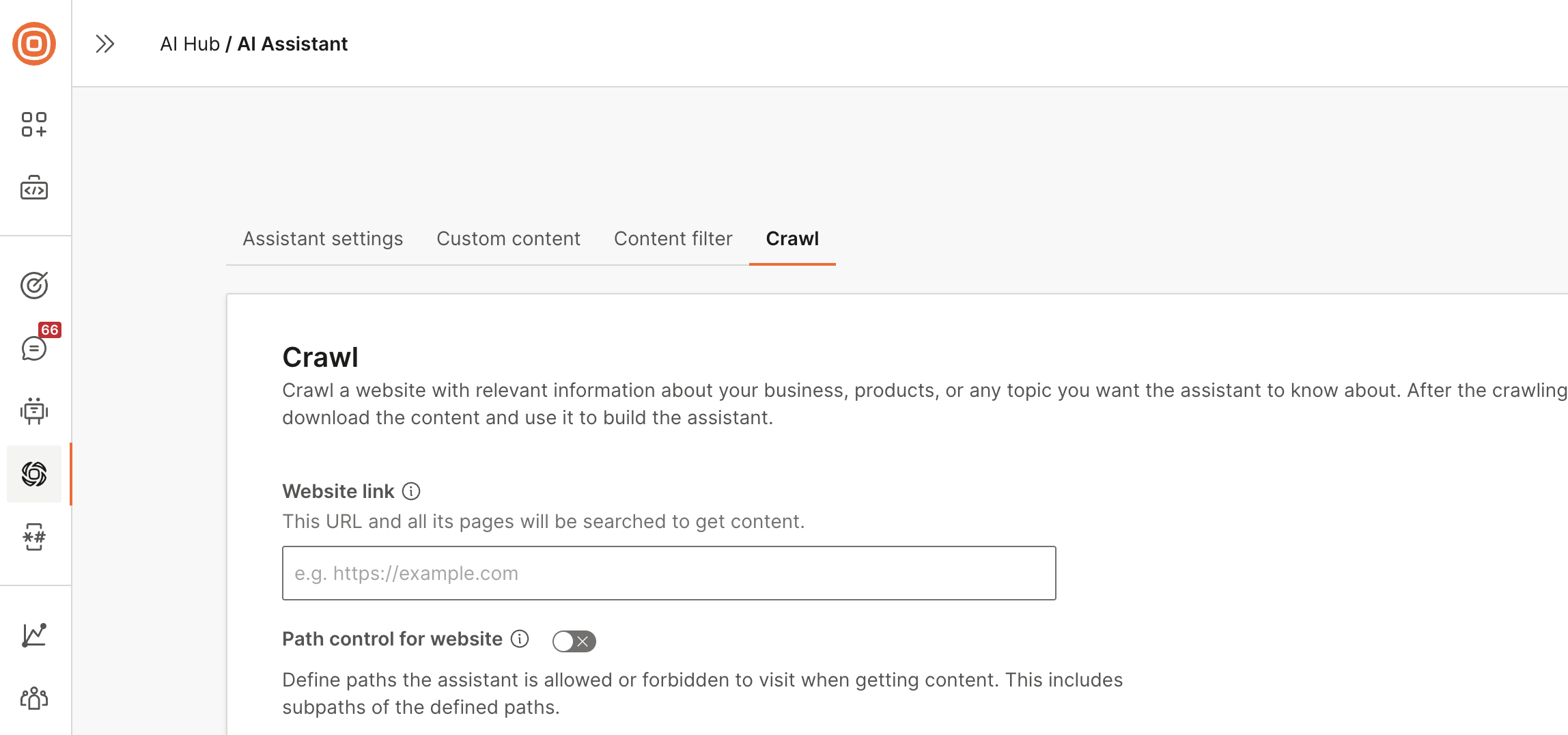
以下を設定します。
-
Web サイトのリンク: Web サイトへのリンクを入力します。アシスタントは、この URL のすべてのページとサブページでコンテンツを検索します。
-
Web サイトのパス コントロール (オプション): このオプションを選択して、アシスタントがコンテンツを取得することを許可または制限するパスを定義します。追加できるパスの数に制限はありません。
-
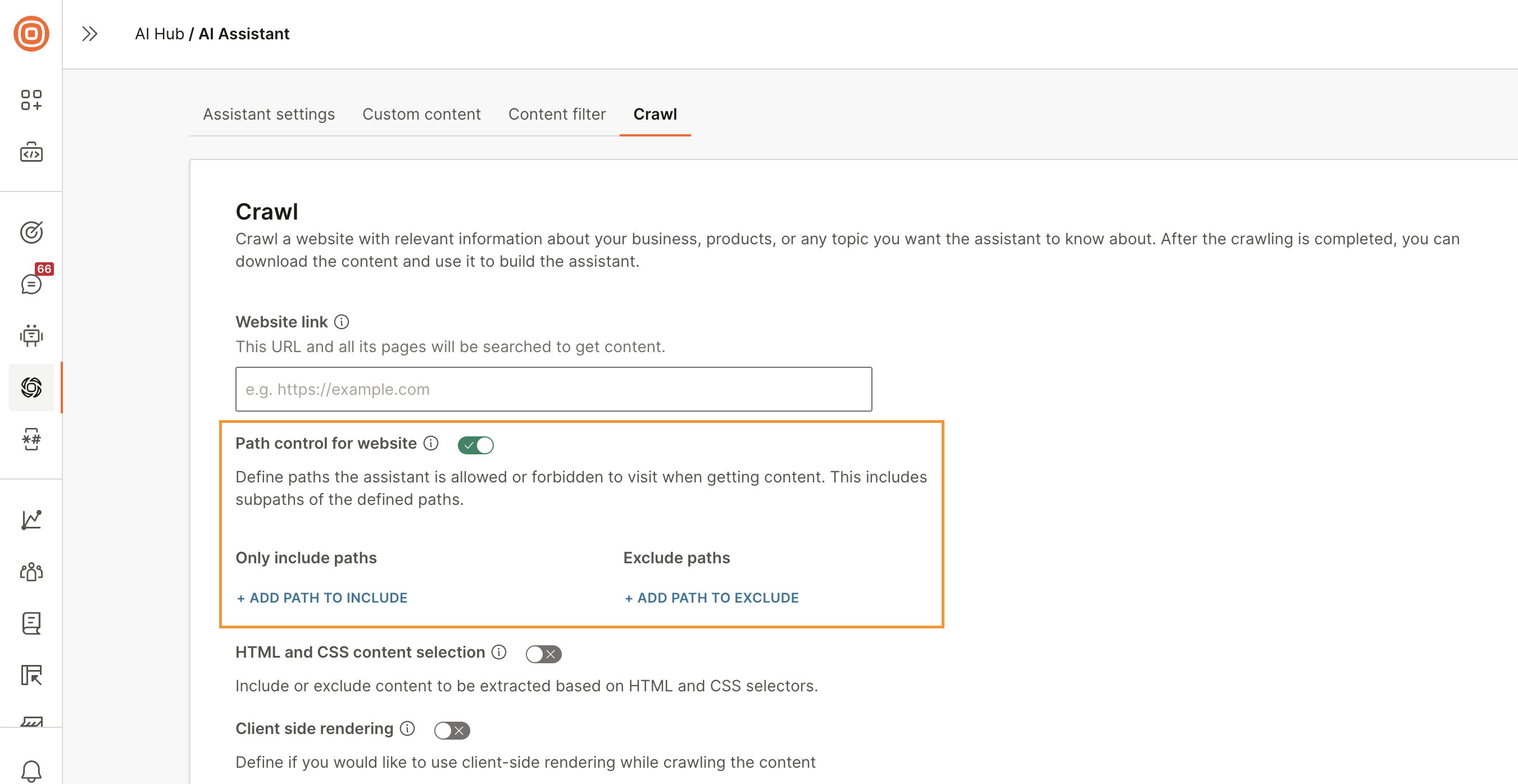
パスのみを含める: アシスタントがコンテンツを検索する必要があるパスを追加します。アシスタントは、これらのパスとそのサブパスからのみコンテンツを取得します。
-
パスを除外する: アシスタントがコンテンツを取得してはならないパスを除外します。アシスタントは、これらのパスのサブパスも除外します。
リンク パスを含める例 パスを除外する例 形容 https:www です。infobip.com/docs Webサイトリンクのすべてのパスとサブパス https:www です。infobip.com/docs /答え
/瞬間https:www 内のすべてのパスとサブパス。infobip.com/docs/answers と https:www.infobip.com/docs/moments https:www です。infobip.com/docs /人
/会話https:www 内のすべてのパスとサブパス。infobip.com/docs、次のパスとサブパス https:www を除きます。infobip.com/docs/conversations https:www.infobip.com/docs/people
-
-
HTML と CSS のコンテンツの選択: HTML と CSS に基づいてコンテンツを含めるか除外します。CSS セレクタを使用して、目的の要素を特定します。
例:
.article__title、.article__body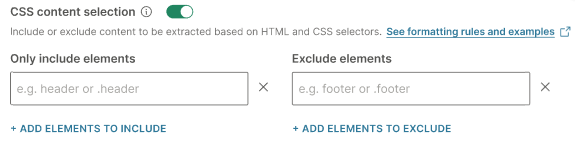
-
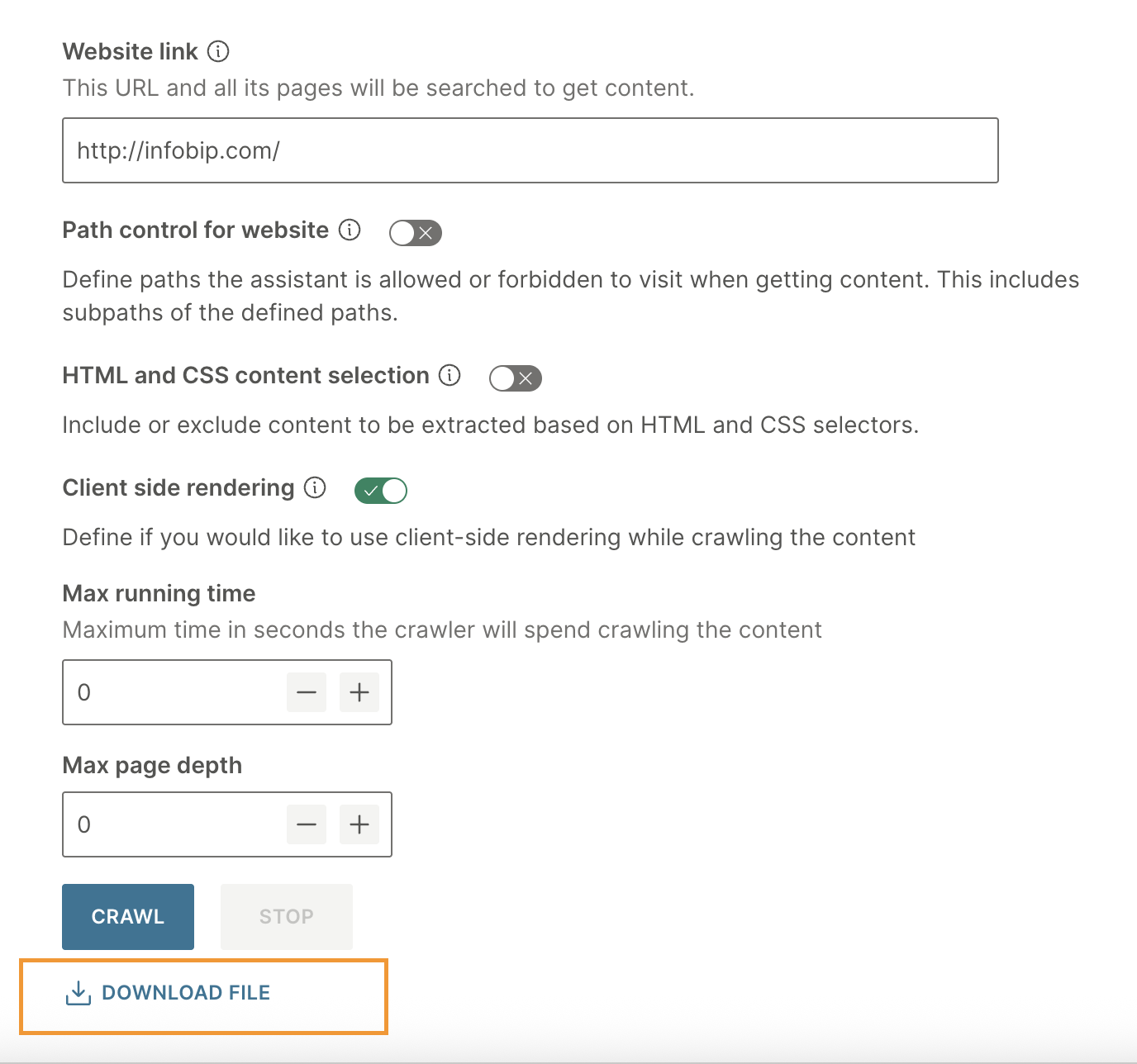
クライアント側レンダリング: コンテンツのクロール中にクライアント側レンダリングを使用するかどうかを定義します。これは、コンテンツを動的に読み込むためにJavaScriptに大きく依存するWebサイトに使用します。
-
最大実行時間: クローラーがコンテンツのクロールに費やす最大時間を秒単位で定義します。
-
ページの最大深度: クロールの深さを定義します。この数値は、クローラーが探索できる開始ページからのクリック数またはリンク数を指します。クロールの深さを高くすると、クローラーは Web サイト内のより深くネストされたページにアクセスできます。
クローラーを起動する [#launch-crawler]
[クロール] を選択して、クローラーを起動します。クロールが完了するまで、このページにとどまります。
クロールが完了したら、出力を含む .zip ファイルをダウンロードします。
アシスタントにドキュメントを追加する [#add-documentation]
-
ダウンロードしたファイルの内容を変更します。独自のドキュメントを作成するセクションのガイドラインを参照してください。
備考運用目的では、最良の結果を得るためにドキュメントを手動で準備します。
クローラーの変更されていない出力は、デモ目的でのみ使用してください。
-
ファイルを AI アシスタントにアップロードします。ドキュメントのアップロード セクションを参照してください。